
How to crawl JavaScript websites using PHP and C#
The most popular PHP methods to obtain the HTML sources from external websites are cURL (Client URL Library) and file_get_contents. These work well when you are crawling a small site without extensive use of JavaScript. For sites that are protected with captcha system that checks for presences of cookies created from its own JavaScript function, these methods will fail.
Example codes to get HTML sources from a URL using PHP cURL
<?php
$url = "https://google.com";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, FALSE);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION , TRUE);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, TRUE);
$html_source = curl_exec($ch);
$http_code = curl_getinfo($ch, CURLINFO_HTTP_CODE);
curl_close($ch);
echo $htmlSource;
?>
To solve this, we need to write a separate program in C# that supports web browser component to perform automated crawling with JavaScript support. The entire system will look like this:
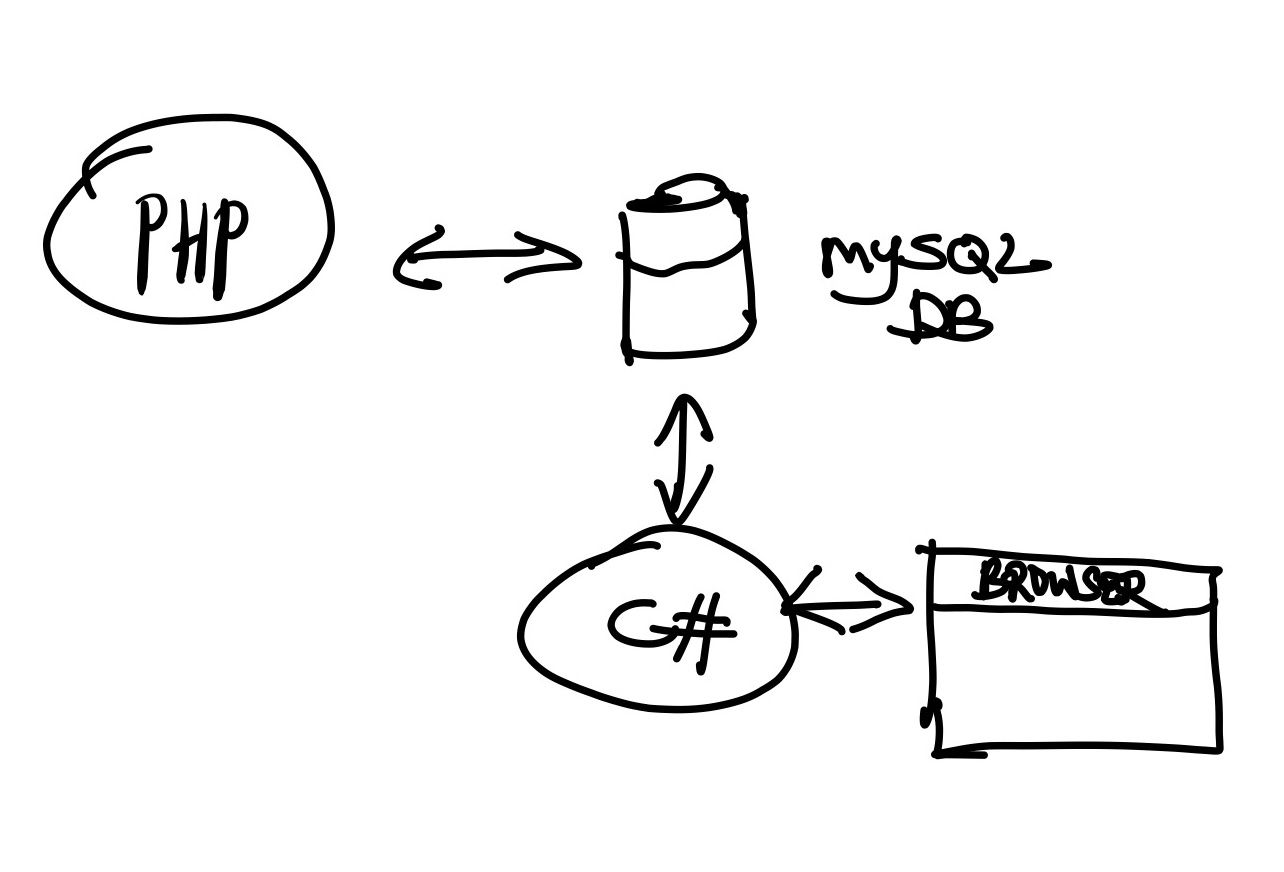
Let's begin to code our web crawler...
MySQL Part
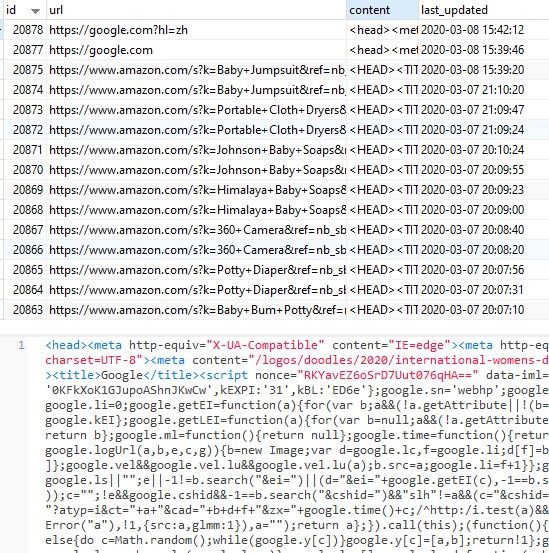
Firstly, we need to build the MySQL DB and 'fetch_page' table. The DB fields should consist of the following essential fields:
- id: record unique id
- url: url reference
- content: store html rendered from web browser component in C#
- last_updated: last datetime of the request
MySQL DB Structure
CREATE TABLE `fetch_page` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`url` varchar(255) NOT NULL,
`content` longtext NOT NULL,
`last_updated` datetime NOT NULL,
PRIMARY KEY (`id`),
KEY `index` (`url`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
PHP Part
Next, we need to write the PHP script that sends the request for C# to crawl and process the returned HTML sources. As this is a pooling request concept, the PHP script should be scheduled to run at a certain interval using Cron Job (Linux) or Task Scheduler (Windows).
// MySQL connection
$servername = "localhost";
$username = "DB_USER";
$password = "DB_PASSWORD";
$dbname = "DB_NAME";
$mysqli = new mysqli($servername, $username, $password, $dbname);
if ($mysqli->connect_error) {
die("Connection failed: " . $mysqli->connect_error);
}
$mysqli->set_charset("utf8");
function fetch_content($mysqli, $url) {
$results = $mysqli->query("SELECT * FROM fetch_page WHERE url='".addslashes($url)."' LIMIT 1");
$cached_row_id = false;
while($cached_row = $results->fetch_object()) {
$cached_row_id = $row->id;
// if found, then return content
if ($row->content != '') return $row->content;
}
//cannot find? insert page url queue for crawling by c#
if ($cached_row_id === false && filter_var($url, FILTER_VALIDATE_URL)) {
$mysqli->query("INSERT into fetch_page SET url='".addslashes($url)."', content='".addslashes('')."', last_updated='".addslashes(date("Y-m-d H:i:s"))."'");
}
return false;
}
With this PHP function, it will create new crawl request record for our C# crawler to work with.
$html = fetch_content($mysqli, "https://google.com");
if ($html !== false) {
// if not empty and content then process html
echo '<h1>HTML fetched</h1>'.htmlspecialchars($html);
}else{
// not found in cached page table or still currently empty (possibly not processed yet by C# crawler)
}
C# Part
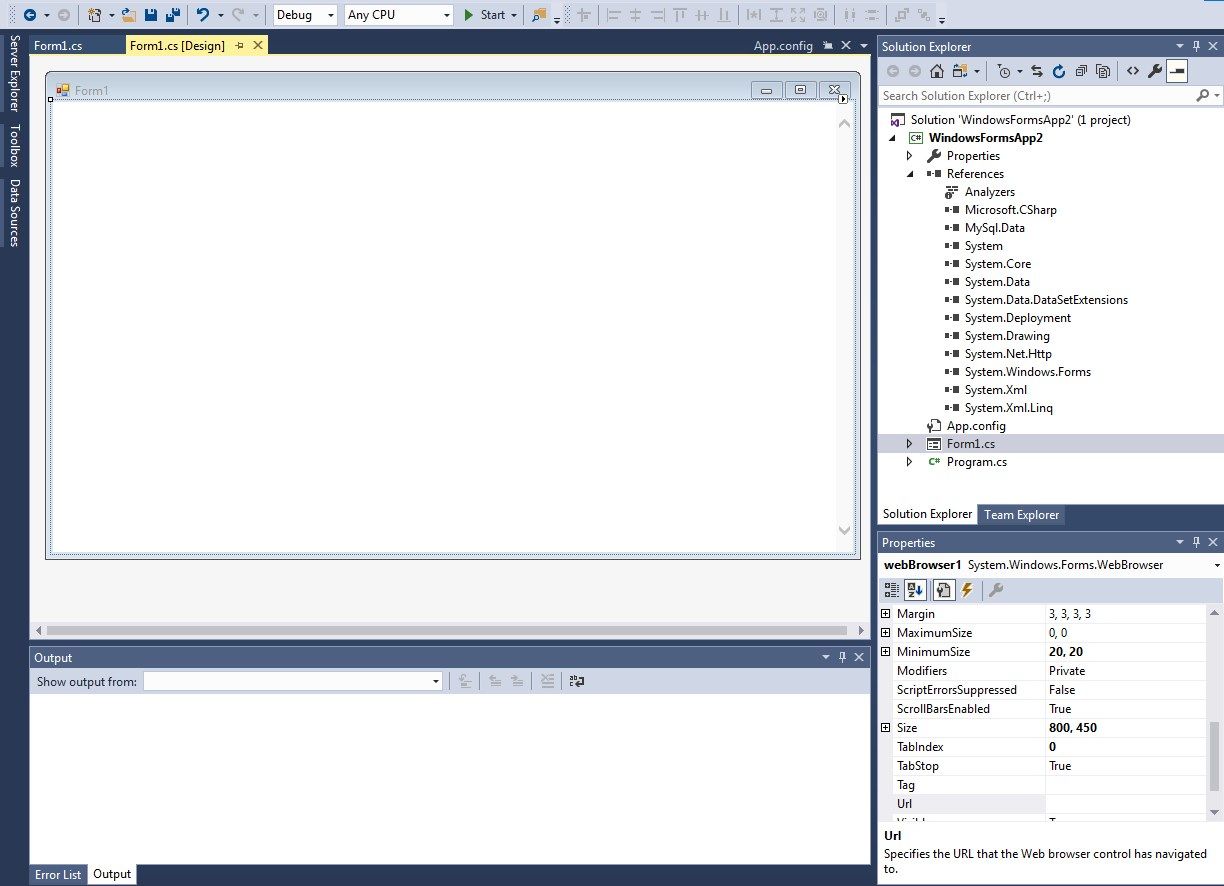
We will be using Visual Studio 2017 for the C# project. You can choose to create a new Windows Form Application. Drag the WebBrowser component to your form and it should appear like shown in the screenshot below.
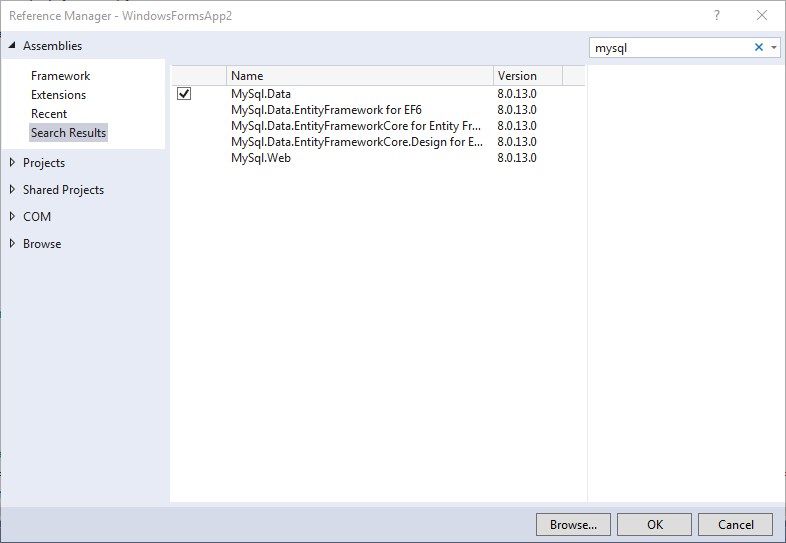
Since we are using MySQL Database for our project, we need to add the Mysql.Data Reference from the Reference Manager dialog.
Next, we add in the following codes to the project and update the DB configurations before building the crawler. The program will loop through each record at a time, checking for new or old requests to perform the next crawl.
using MySql.Data.MySqlClient;
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
namespace WindowsFormsApp2
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
private async void Form1_Load(object sender, EventArgs e)
{
MySqlConnection conn;
string connStr = "server=localhost;user=YOUR_DB_USER;database=YOUR_DB_NAME;port=3306;password=YOUR_DB_PASSWORD";
conn = new MySqlConnection(connStr);
conn.Open();
do
{
//done, crawl next url
await crawl_next(conn);
} while (true);
}
async Task<string[]> DownloadAsync(string url, string id)
{
TaskCompletionSource<bool> onloadTcs = new TaskCompletionSource<bool>();
this.webBrowser1.ScriptErrorsSuppressed = true;
// Navigate to url
this.webBrowser1.Navigate(url);
string[] obj = new string[] { };
dynamic doc = null;
do
{
await Task.Delay(5000);
doc = this.webBrowser1.Document.DomDocument;
} while (doc == null);
string html = "";
try
{
html = doc.documentElement.innerHTML;
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
html = "";
}
obj = new string[] { id, html };
return obj;
}
async Task crawl_next(MySqlConnection conn) {
try
{
//if crawled before, don't recrawl the same page for 1 week
string sql = "SELECT * FROM fetch_page WHERE content = '' OR last_updated < NOW() - INTERVAL 1 WEEK LIMIT 1";
MySqlCommand cmd = new MySqlCommand(sql, conn);
cmd.CommandTimeout = 0;
MySqlDataReader rdr = cmd.ExecuteReader();
string url = null;
string id = null;
while (rdr.Read())
{
url = rdr["url"].ToString();
id = rdr["id"].ToString();
}
rdr.Close();
if (url != null && id != null)
{
//reupdate to table if content is ready
await DownloadAsync(url, id).ContinueWith(
(task) =>
{
try
{
//MessageBox.Show("Fetched: "+rdr["url"]);
MySqlCommand addcmd = new MySqlCommand("UPDATE fetch_page SET content=@content, last_updated=NOW() WHERE id=@id", conn);
addcmd.CommandTimeout = 0;
addcmd.Parameters.AddWithValue("@id", task.Result[0]);
addcmd.Parameters.AddWithValue("@content", task.Result[1]);
addcmd.ExecuteNonQuery(); //update DB
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
},
TaskScheduler.FromCurrentSynchronizationContext());
}
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
}
}
}
Conclusion
There are many applications when it comes to web crawling functionality. You can build a database of big data useful for analytics as well as to replace manual data entry work. This project can be further extended to include functions to detect Captcha page so user can intervene directly on the webbrowser component.
Do you need a custom web crawler to complete certain job? Feel free to reach out to me to discuss your requirements.